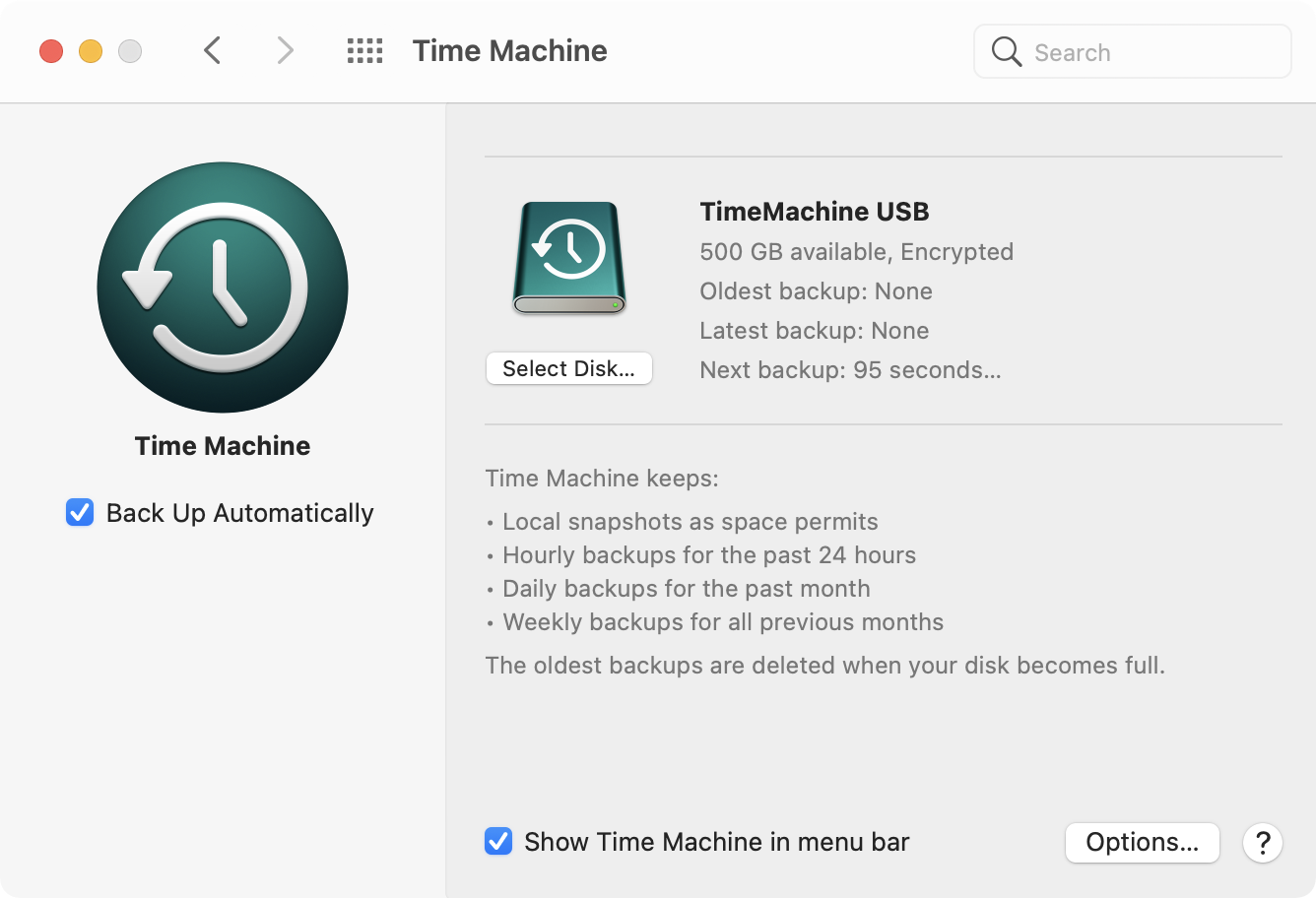
Tesla’s Wall Connector is a reasonable choice for a wall box in the EU market. A single, relatively inexpensive product (535 euro in Italy) can work on both single- and three-phase systems and can handle up to 22 kW charging.
Though an additional Neurio Meter (which to my knowledge is no longer sold by Tesla) can enable dynamic load balancing (e.g. you can limit the total amount of power your house can draw by limiting EV charging), a lesser known feature can come in handy. Germany’s §14a EnWG Curtailment regulation requires power-hungry devices to be able to be deactivated or brought to under 6A per phase by the power company. Tesla’s Wall Connector complies with such regulation and allows using the RS485 connection on the unit to be used as a dry contact to enable/disable curtailing.
Wiring and configuration
To enable the device’s hotspot required for configuration, you can either turn the power off and then on again, or you can press and hold the button on the charger’s handle until the lights on the unit start blinking.
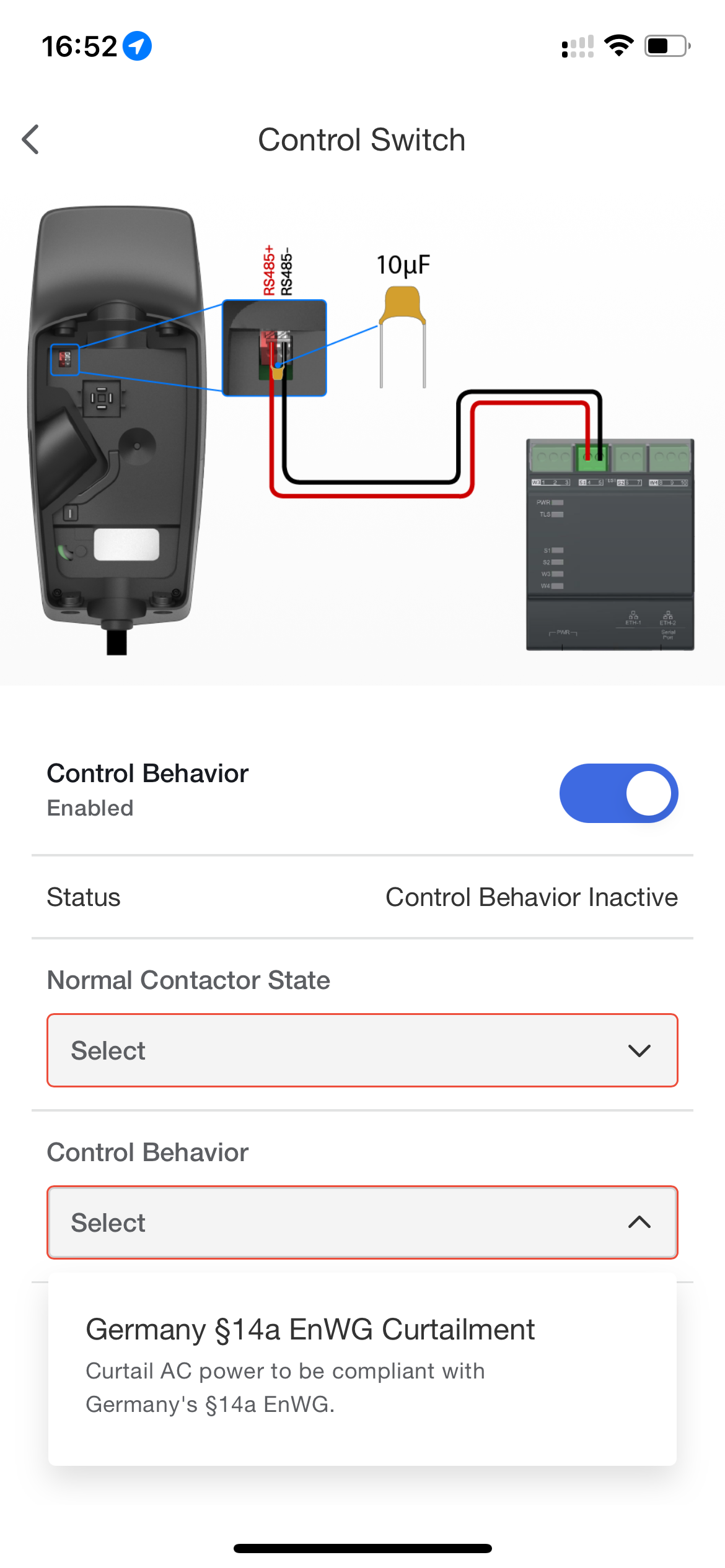
As shown in the Tesla One app screenshot above, you need to place a 10µF capacitor across the RS485 terminals, and then wire your relay/switch to them. You can use the Tesla One app to configure the contactor state to be either normally open (open circuit = no power limit) or normally closed (open circuit = limiter active).
Results
After saving your configuration, by toggling the relay/switch you can either let the car draw the current it wants up to the charger’s limit (adjustable in Tesla One, up to 32A) or limit it to 6A. This means that you will get roughly 4 kW while on a three-phase circuit or 1.4 kW on a single-phase one. The change happens almost in real time and is reversible: you can go back and forth between limited and unlimited without ever interrupting the charging session or disconnecting the vehicle. When the curtailing is active, the Wall Connector will signal it with a blinking red light, in addition to the usual “green waterfall” shown when charging. It can be somewhat confusing when the red LED blinks without a charging vehicle, as it will be the only light visible on the charger, possibly suggesting that it has some fault.
Possible use cases
This can be handy in some cases, for example holiday rentals could easily throttle guests to slower charging while enabling faster charging for the owners.
Here in Italy the default home power supply is a paltry 3 kW single phase, which can be easily be bumped to 6 kW. That is still ridiculously low for this day and age, but Italians are just used to micro manage what appliances are running to prevent their power from being cut. Not many people, though, know that their meters allow 133% power draw (139% for three-phase supplies) for up to 180 minutes, which reset after 15 minutes within the limits. I exploit this very fact to charge my car at 11A three-phase (which usually works out to 7.7-7.8 kW) on my 6 kW three-phase supply. I just run some clever Home Assistant automations to change the car’s charging amps to charge as fast as possible while avoiding power cuts. Should the car loose internet connectivity, though, my automations will fail and my power draw will exceed the 3-hours grace period, my power would be cut and I would have to manually turn the meter’s breaker back on. This can act a since failsafe mechanism, as I can hardwire a smart switch to make sure I can restrict the maximum power draw of the car to 4 kW, no matter what the car does. Since I mostly charge by night when cheaper rates are available, it’s unlikely I will have > 2 kW sustained loads, thus the chance of getting my power cut is minimal.







 Not my printer, but the message is the same.
Not my printer, but the message is the same.